The Visualization toolkit (vtk) is a freely available C++ class library for 3D graphics and visualization. The toolkit was developed at GE Corporate Research and Development. The authors of the toolkit had a lot of experience with a proprietary system that they had developed for a number of years. [13] Using their experience, they were able to design a simple, portable, powerful, and flexible toolkit that is widely used today.
The vtk model is based on the data-flow paradigm [13]. In this paradigm, modules are connected to form a network which is referred to as a vtk pipeline. The modules perform algorithmic operations on the data as it flows through the pipeline. In the vtk model, there are two basic types of objects: process objects and data objects. Process objects are the modules in the pipeline. Data objects represent the data at various stages in the pipeline. Essentially, the developer is only aware of the process objects, the data objects "live" in-between the process objects.
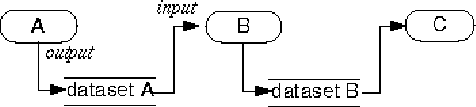
Figure 3.4: vtk model. Process objects A, B, and C are source, filter, and
mapper objects, respectively.
Process objects can be one of three types: sources, filters, and mappers. Source objects are found at the beginning of the pipleline. They generate one or more output datasets. A source object may be a reader for a particular file type or it may even generate its own data, such as a sphere source. The output of this source object is then connected to the input of another process object. The act of connecting the input of one process object to the output of another process object is how the pipeline is built. For instance, to connect the output of filter A to the input of filter B, a construct of the following form is used:
B->SetInput( A->GetOutput() );
Each process object has only one output. However, fanning of the output is allowed since multiple process objects can set their input to be the output of the same process object. The pipeline terminates with mappers. A mapper "maps" its input to the screen (renders it). At this stage of the pipeline, the input to the mapper is the output of some filter that outputs geometry data (vtkPolyData). Geometry data (vtkPolyData) is a data object, just like any other data object. In fact, there are filters that work on geometry data such as a decimation algorithm (vtkDecimate) or a triangulation algorithm (vtkTriangleFilter).
The mapper itself is one component of an object called a vtkActor. A vtkActor represents a geometrical object and its attributes. Other information in a vtkActor includes the object's appearance attributes (vtkProperty), and its location in space. As a result, the developer will instantiate a vtkActor for each mapper in the vtk pipeline. The developer will then set any attributes of each vtkActor and add each vtkActor to what is called a vtkRenderWindow. The vtkRenderWindow will then display all of its actors in a window on the screen.
In this work, however, we do not make use of vtk's rendering capabilities since they are insufficient for VR environments like the CAVE. Rather then putting the vtkActors into a vtkRenderWindow, the vtkActors are translated to Performer structures and rendered using Performer. This process is discussed in detail in later sections.
Building vtk pipelines is simple, but one also needs to understand how
a vtk pipeline executes. vtk uses a model that has an implicit control
of execution [14]. Execution only occurs when output is requested from
an object (i.e. demand-driven). This scheme is implemented with two
key methods: Update() and Execute().
Each process object keeps track of its last modification time.
If output is requested from the object and the object or
its input has been modified since it last executed, then the process
object should re-execute. The process of executing the pipeline begins
with a call to a process object's Update() method. This typically
happens when it is time to render and the mapper wants to update itself
before rendering. The process object that receives the Update()
message will recursively invoke the method on its input. This continues
until a source object is encountered. The source object compares its
modification time to the last time it executed. If it has been modified,
then it will re-execute itself using the Execute() method. As
mentioned previously, data objects "live" between process objects. If
the source object has not been modified, then its output (a data object)
is still valid. The recursion then backtracks with each successive process
object comparing its input time and its own modification time with the
time that it last executed. If necessary, the process object re-executes
itself using the Execute() method. This process ends when control
is returned to the object that initiated the Update().
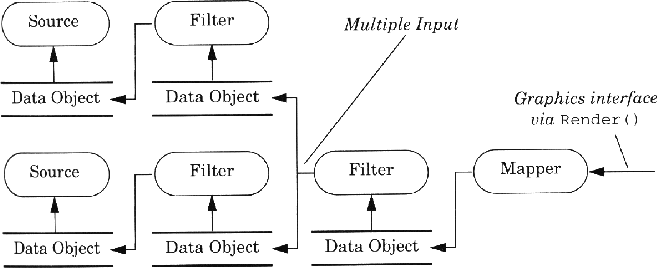
Figure 3.5: vtk model. Arrows indicate direction of Update() process. Data
flows back to mapper via Execute().
The process is simple, but it requires that modification times and execution times are kept track of properly. This is especially important if the developer chooses to write custom process objects. The benefits of this approach are that segments of the pipeline are only re-executed when their output is requested and only if they have changed since the last execution.
Overall, the vtk toolkit is simple to use and very powerful. The power comes from the fact that vtk comes with more than 300 classes. Also, since it is freely distributed, users contribute code and bug fixes. The library also comes with wrappings that allow it to be used with interpreted languages such as Tcl, Java, and Python. These languages offer greater flexibility and cut down on development time [13].